Bucket Hat Template
Bucket Hat Template - A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. The benchmark comprises of 161 programming problems; While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. The benchmark comprises of 161 programming problems; One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. One common approach is training models to refuse unsafe queries, but this strategy. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. While foundation models have shown promise across a variety of fields, astronomy lacks a. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. Our analysis yields a novel. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. We introduce clever, the first curated benchmark for evaluating the. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. We introduce clever, the first curated benchmark for evaluating. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. While foundation models have shown promise across a variety of. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A fundamental limitation of current ai agents is their inability to learn complex skills. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. The benchmark comprises of 161 programming problems; We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. While foundation models have shown promise across. The benchmark comprises of 161 programming problems; While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A. The benchmark comprises of 161 programming problems; We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. A fundamental limitation of current ai agents is their. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. We introduce clever,. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. The benchmark comprises of 161 programming problems; A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. A fundamental limitation of. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. Our analysis yields. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. While, as we mentioned earlier, there can be thorny “clever hans”. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. The benchmark comprises of 161 programming problems; One common approach is training models to refuse. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. A fundamental limitation of. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. We introduce clever, the first curated benchmark for evaluating. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. The benchmark comprises of 161 programming problems; While, as we. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. One common approach is training models to refuse unsafe queries, but this strategy. Our analysis yields a novel robustness metric called clever, which is short for cross lipschitz extreme value for network robustness. The benchmark comprises of 161 programming problems; While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. While, as we mentioned earlier, there can be. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A fundamental. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. The benchmark comprises of 161 programming problems; While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm. The benchmark comprises of 161 programming problems; While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. A fundamental limitation of current ai agents is their. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. The benchmark comprises of 161 programming problems; While foundation models have. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. While foundation models. The benchmark comprises of 161 programming problems; While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. We introduce clever, the first curated benchmark for evaluating the generation of specifications and formally verified code in lean. A fundamental limitation of current ai agents is their inability to learn complex skills on the. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. Our analysis yields a novel. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. The benchmark comprises of 161 programming problems; One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. The benchmark. While foundation models have shown promise across a variety of fields, astronomy lacks a unified framework for joint modeling across its highly diverse data modalities. A fundamental limitation of current ai agents is their inability to learn complex skills on the fly at test time, often behaving like “clever but clueless interns” in novel environments. While, as we mentioned earlier, there can be thorny “clever hans” issues about humans prompting llms, an automated verifier mechanically backprompting the llm doesn’t suffer from these. One common approach is training models to refuse unsafe queries, but this strategy can be vulnerable to clever prompts, often referred to as jailbreak attacks, which can trick the ai into. The benchmark comprises of 161 programming problems;
BUCKET HAT VIDEO + FREE PATTERN MADE EVERYDAY

11 Sewing Pattern Bucket Hat Images, Stock Photos, 3D objects

Free crochet bucket hat pattern Artofit

The bucket hat free sewing pattern Artofit

Template Free Bucket Hat Pattern

Bucket hat pdf pattern free Artofit

1,330 imágenes de Bucket hat template Imágenes, fotos y vectores de

Crochet Bucket Hat Pattern (FREE) Crochet Dreamz

Printable Bucket Hat Pattern

Mens Bucket Hat Sewing Pattern at Ashley Nugent blog

Bucket hat sewing patterns for men women kids 5 free printable pdf

Perfect free bucket hat pattern in 5 sizes Artofit

Bucket Hat Template Vector Illustration Cloth Outdoor Vector Vector
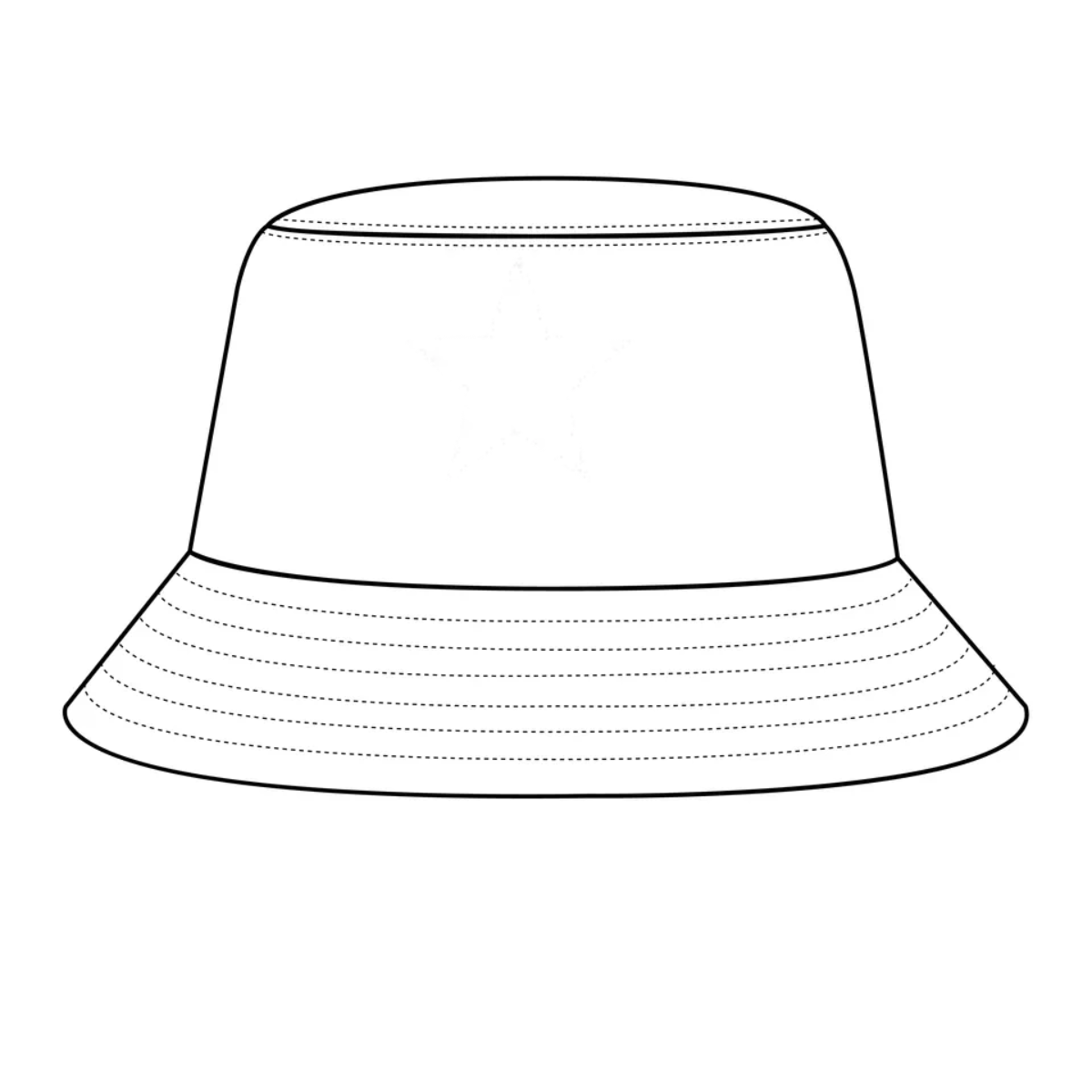
Cartoon Bucket Hat Drawing at Rebecca Leon blog

Crochet Bucket Hat In 1 Day Free Pattern • Craft Passion

How to make a bucket hat patterns Artofit

Free Bucket Hat Sewing Pattern • Heather Handmade

BUCKET HAT PATTERN RUBY

Diy reversible bucket hat how to make a hat free pattern sewing
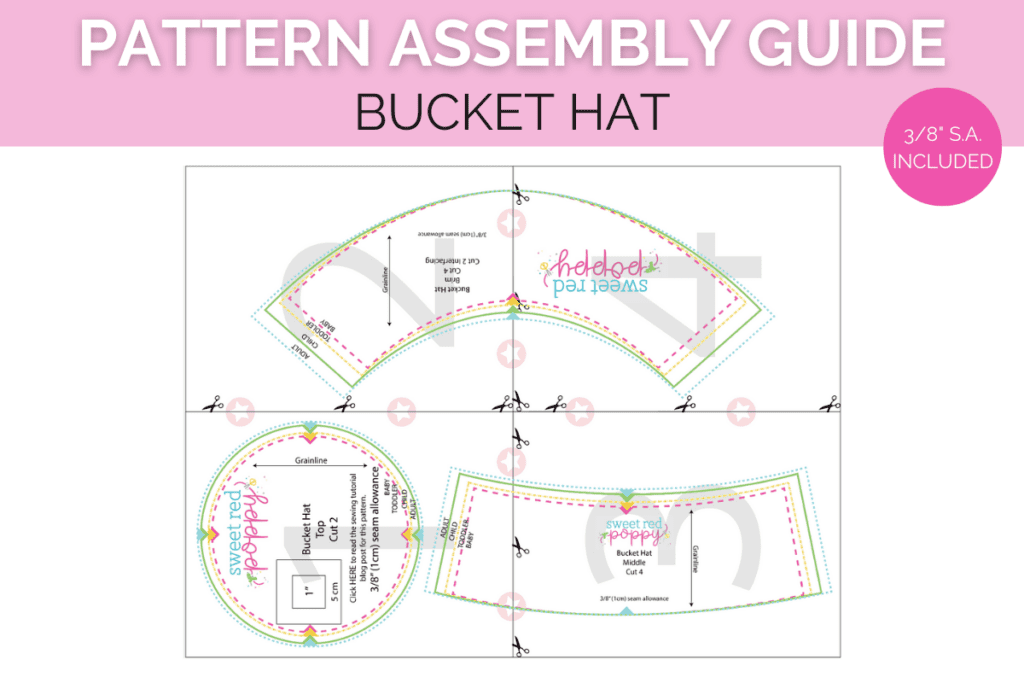
Bucket Hat Template
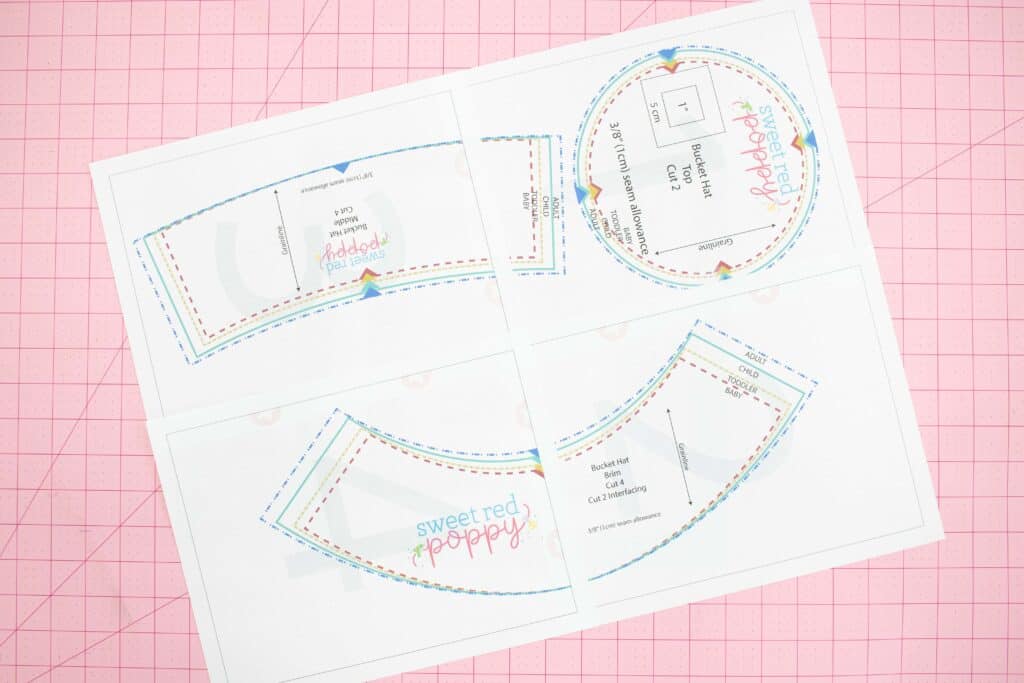
Bucket Hat Sewing Pattern US sewing Sweet Red Poppy

Free Bucket Hat Pattern Printable

Free bucket hat sewing pattern Artofit

Template Free Bucket Hat Pattern Pattern Matching Algorithms

Simple Bucket Hat Sewing Pattern at Hugo Carter blog

Fashion Hat Vector

Women s free bucket hat sewing pattern Artofit

Free Crochet Bucket Hat Pattern Sunny Stitches Hat Maisie and Ruth

Free Printable Labubu Bucket Hat Pattern
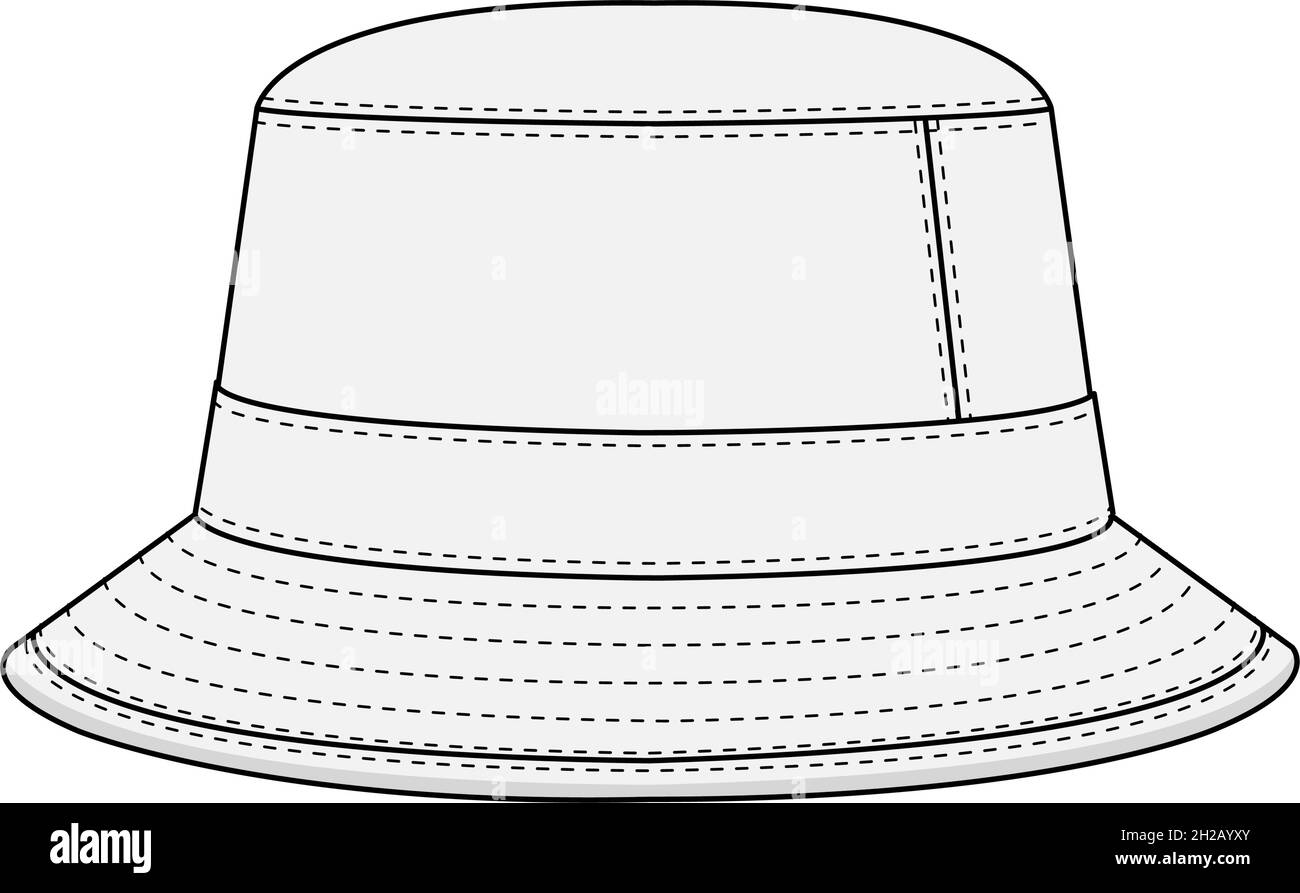
Bucket hat template vector illustration Stock Vector Image & Art Alamy
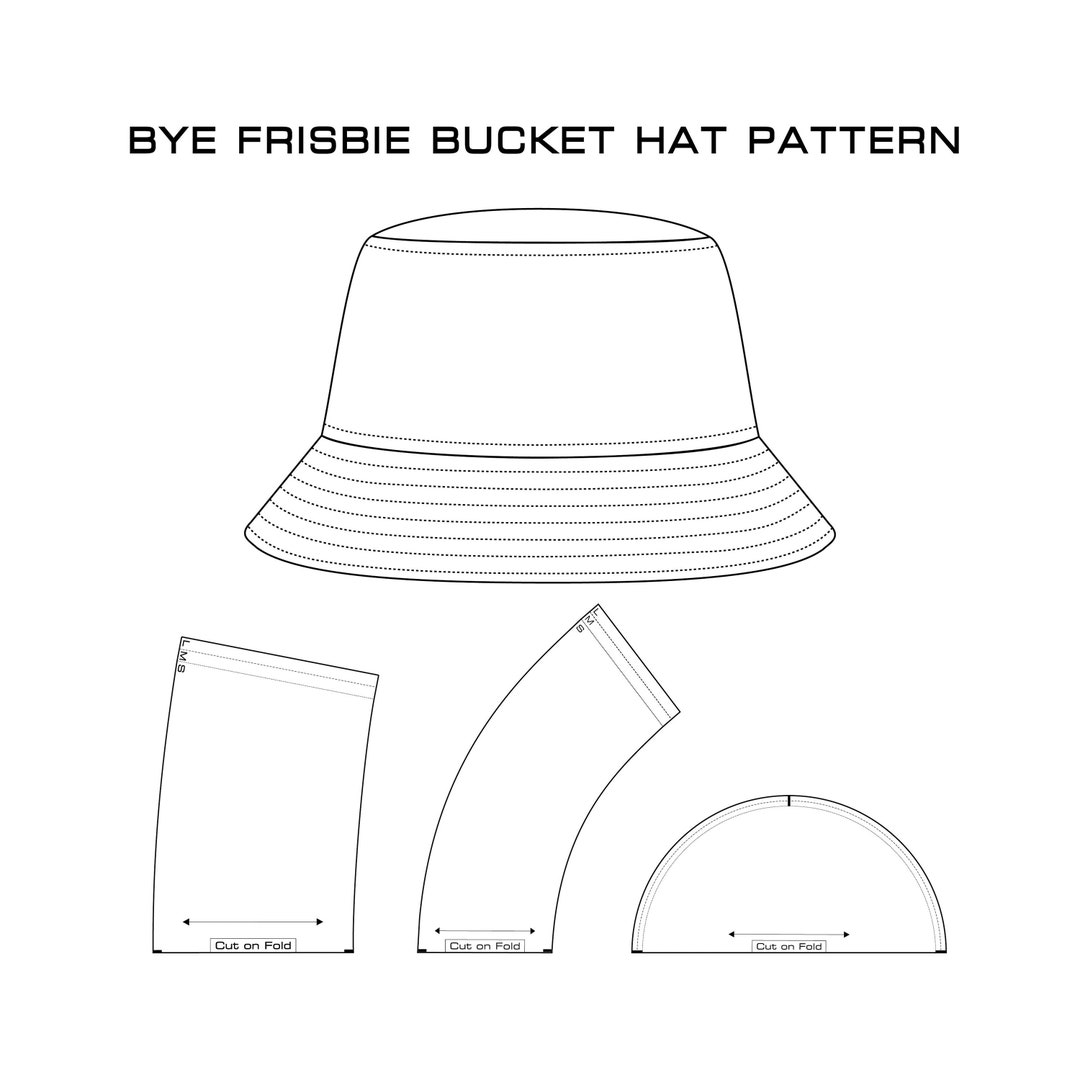
Bucket Hat Sewing Pattern for Beginners to Experts PDF Download With
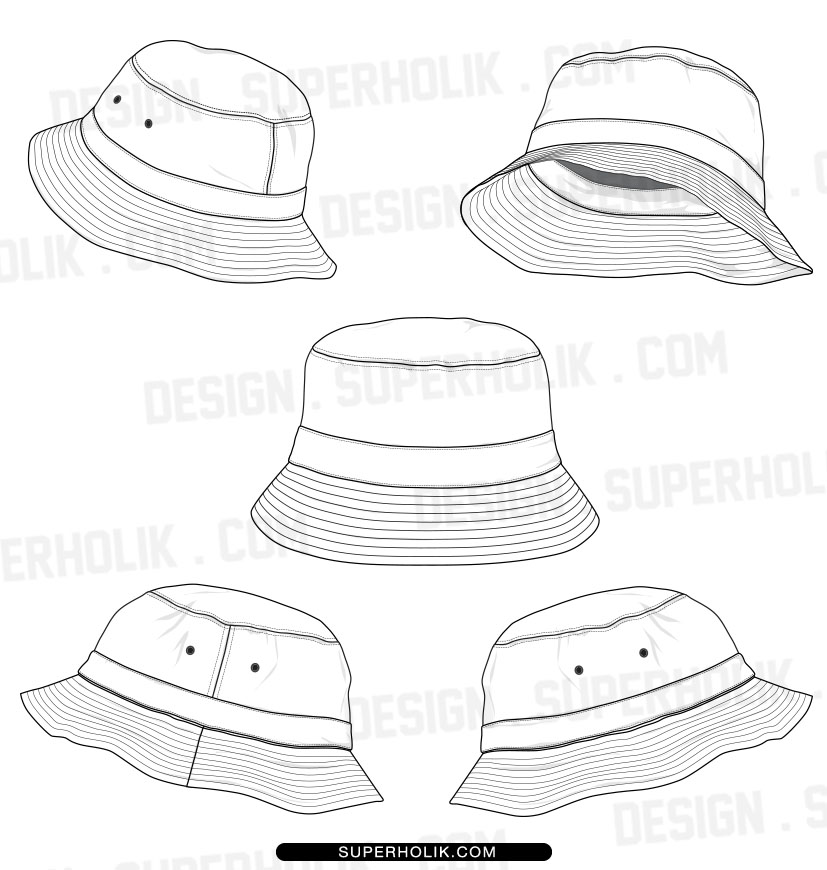
Bucket Hat Template Vector at Collection of Bucket
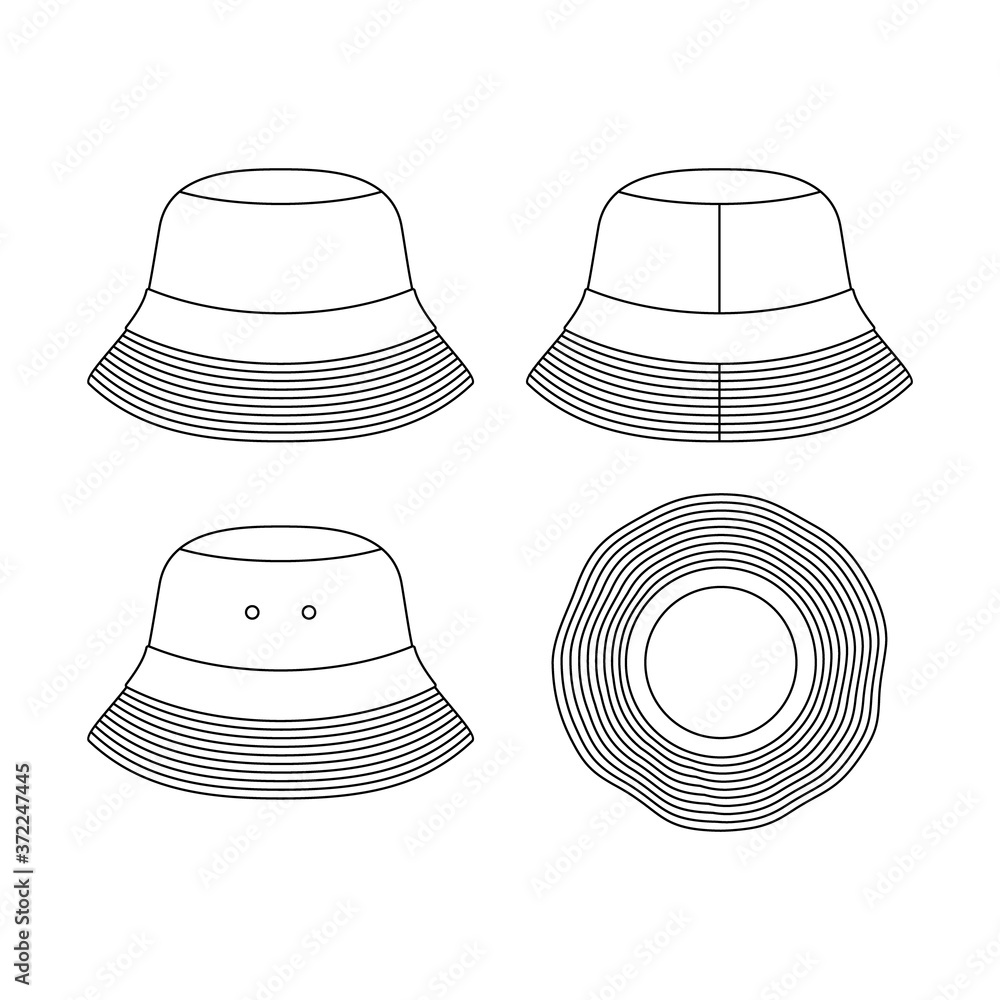
Bucket Hat Template
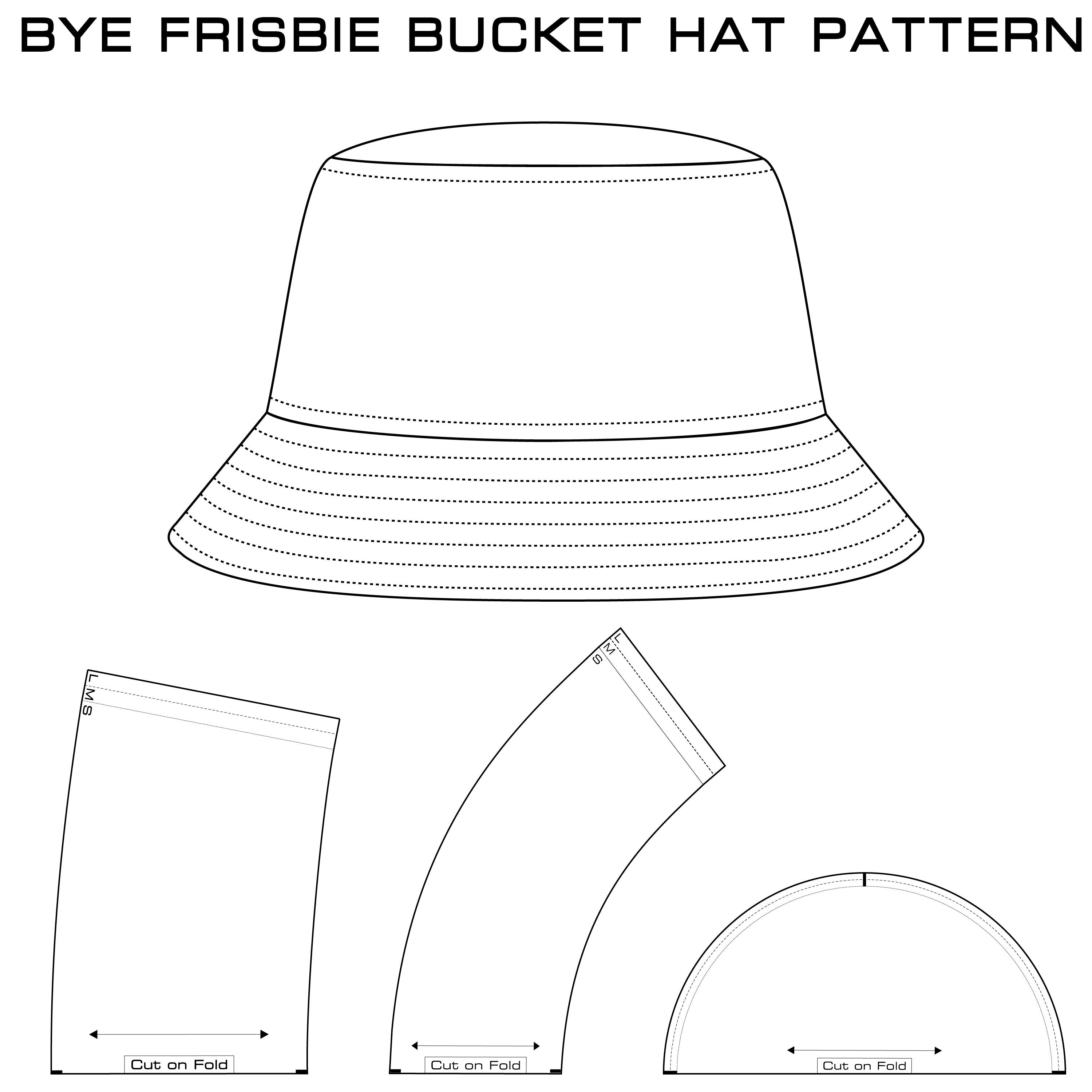
Hello Sewing Bucket Hat Pattern at Ryan Henderson blog

Free Sewing Pattern For A Bucket Hat at Ann Burkett blog
Our Analysis Yields A Novel Robustness Metric Called Clever, Which Is Short For Cross Lipschitz Extreme Value For Network Robustness.
We Introduce Clever, The First Curated Benchmark For Evaluating The Generation Of Specifications And Formally Verified Code In Lean.
Related Post: